Hello dear readers,
Today I want to start a discussion about SW complexity metrics and SW reliability models. Why? Hmm .. good question. So, some motivation in this post.
Majority of the dependability attributes are X-abilities. Where, X = Reli, Maintain, Avail (well, only three of them, but you get the idea). They are so-called Non Functional Properties (NFP) of the system. The wiki gives a complete list of the NFPs.
Typically NFPs are defined in terms of probability. For instance, one of definitions of system reliability: "The probability that a system will perform its intended function during a specified period of time under stated conditions". See - the probability of blah blah blah.
This definition originally addresses to HW domain or Traditional Reliability. Using different standards, testing approaches, statistical observation we can estimate such probabilities for a HW part of the system. Moreover, we can define not only the probability of failure-free execution, but a time-depending failure rate. It usually looks like a bathtub ("bathtub curve"):

Failure rate are linked with well-known reliability metrics like MTTF (Mean Time To Failure) or MTBF (Mean Time Between Failures). HW fails at the beggining of utilization (infant mortality) and at the end - because of wear out. If you'll try to map this concept to the SW you'll see something like this:
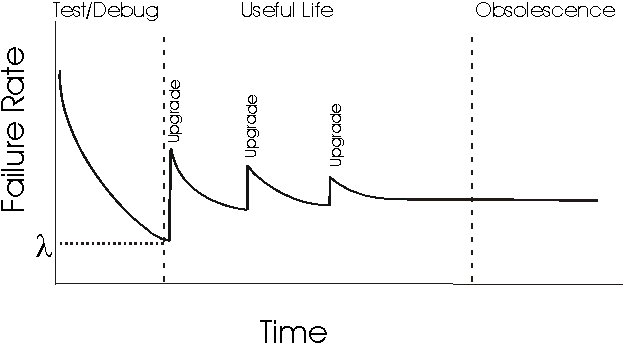
Short explanation of the SW-curve: SW reliability mostly depends on the number of unfixed bugs within the program. The curve shows that majority of these bugs can be handled during the testing phase of SDLC. Each new upgrade contains new bugs and makes the system more unreliable. It looks fine and gives an opportunity to evaluate reliability of SW+HW systems.
But ... there is a question - how to evaluate these probabilities of failure, failure rates, numbers of bugs, whatever of the new SW product? Run it 100000 times? Using what inputs? How to obtain info about operational profile of the system before utilization? and so on.
One of the answers - by an application of Software Complexity Metrics (SCM) and Software Reliability Models (SRM). The SW reliability community is agreed with the following assumption: There is a straight forward correlation between SW reliability and a number of bugs. Something like that:
Pr ( Failure ) = N_unfixed_bugs * some_coefficient
Initial number of unfixed bugs is evaluated using SCMs. SRMs, particularly growth and curve-fitting models, model the process of bug fixing and reliability increasing with the time.
No comments:
Post a Comment